
Vjerujem da i vi u svakodnevnom radu na računalu u većoj ili manjoj mjeri koristite kompresiju podataka, bilo to svjesno tako da šaljete i primate zipane arhive te upakiravate više povezanih datoteka u jednu kako bi ju bilo lakše podijeliti s drugima ili to čini računalo pa da to i ne primijetite. Zasigurno ste se barem jednom upitali prilikom izrade neke takve arhive, a što se tu zapravo događa ili kako radi zip te kakvih sve algoritama ima. Ovo će nam biti polazna točka, odnosno pogledati ćemo nešto detaljnije u sam proces kompresije. Odmah da se napomene, cijeli taj proces je složen i postoji mnogo stručnih radova na tu temu te se ti algoritmi i dalje usavršavaju.


Također, ima tu i matematike i ne baš jednostavnih modela kojima se nastoji postići što bolji omjer kompresije, što manje gubitke te da se zauzme što manje prostora kojega datoteka uzima na disku. Ovisno o namjeni i namjeri postoji više algoritama pa ćemo proći ukratko o nekim bitnijima i objasniti kada se koji koristi. Pa da utvrdimo što je uopće kompresija. Osim što može biti sa ili bez gubitaka, ugrubo bismo mogli reći da je kompresija postupak kojim određeni kod zapisan na računalu činimo manjim uz uvjet da zadržava svoj smisao. To se uglavnom radi metodama predviđanja gdje će se pojaviti koji podatak i u slučaju kompresije s gubicima neke dijelove datoteke ćemo izgubiti, ali ćemo ujedno i postići bolji omjer kompresije. Često je baš to slučaj za slike, video i audio datoteke gdje ljudska osjetila u stvari i neće primijetiti razliku ili budu ali je u prihvatljivim razmjerima s obzirom na dobitak kompresije. U slučaju kompresije bez gubitaka imamo algoritam koji određeni kod sažme te prilikom dekompresije imamo u potpunosti iste podatke kao i prije samog procesa te se ovaj postupak onda provodi primjerice za tekstualne datoteke gdje bi se gubitak određenog podatka očigledno primijetio. Uzmimo za jednostavan primjer video zapis gdje jedan oktet sadrži podatke za tek vrlo mali dio prikaza jednog framea. Ukoliko dođe do gubitka te informacije mi nećemo tu ništa primijetiti, međutim imamo li primjer s tekstualnom datotekom gdje je jedan znak opisan za jednim oktetom i ako taj oktet predstavlja slovo ‘a’ pri promjeni bismo vrlo brzo primijetili da nemamo više slovo ‘a’ već neki drugi znak. Postoji i jedna tematika koja se već neko vrijeme provlači i počela je s ubrzanim povećanjem memorijskog prostora na prijenosnim medijima, a to je MP3 format protiv FLAC-a(Free Lossless Audio Codec). MP3 koristi kompresiju s gubicima, dok je FLAC bez gubitaka te argumenti na jednoj strani su da je MP3 loš izbor što se tiče kvalitete, dok druga kaže da je FLAC prerobustan. Iako postoji popriličan broj rasprava na Internetu po toj tematici vrlo vjerojatno je da će oboje zvučati dosta blisko ako ne i isto što najviše ovisi o hardveru na kojem se određeni audio zapis izvodi. Tako da ako posjedujete fenomenalnu zvučnu karticu, zvučnike i pripadajuću programsku podršku možda možete primijetiti neke razlike. Kada se spomene pojam kompresije svi obično pomisle na ZIP i RAR međutim kompresija u stvari ima puno širu primjenu koje danas u svakodnevnom radu i nismo svjesni. Razno razni formati za audio i video te slikovne podatke koriste kompresiju kako bi spremanje tih podataka zauzelo manje mjesta te kako bi njihov prijenos trajao kraće. Iako danas imamo memorijske kartice, USB stickove za pohranu podataka koji imaju znatno više prostora nego ranijih godina, na velik broj određenih datoteka ipak se može primijetiti razlika. Prije desetak godina i pojave nekog oblika bržeg pristupa Internetu nikome nije bilo svejedno hoće preuzimati datoteku veličine 6 ili 3 MB te vidimo da je to u stvari jedan veoma potreban postupak koji svoje primjene nalazi svuda.
Osnovna je pretpostavka kada govorimo o kompresiji da su određeni podaci “višak” ili da se može točnim procjenama i algoritmima složiti uzorak podataka te na taj način da predvidimo gdje se uzorak pojavljuje. Uzorci koji se pojavljuju češće trebati će manje bitova, manje informacija da ih se opiše od onih koji se pojavljuju rjeđe pri postupku kompresije. Već sada je moguće zaključiti da algoritam radi u više prohoda kroz podatke te imamo dio u kojem se podaci analiziraju i rade procjene putem stohastičkih metoda, dok je idući korak kodiranje odnosno primjena tih metoda za izradu izlazne datoteke. Algoritam mora vrijediti za bilo koji skup podataka da dobije na ulazu za kompresiju, a podaci mogu biti najrazličitiji. To znači da će se jedan skup podataka moći bolje, a drugi lošije provesti ovisno o samom njihovom sadržaju. Uzmemo li ogledni primjer za slučaj videa, analizirajmo dva susjedna framea i ako su njihove razlike minimalne, primjerice gledamo nešto gdje nema puno pokreta, tada će biti potrebno manje informacija za zapisati takvo nešto, nego u slučaju da gledamo atletiku ili utrku Formule 1 gdje su promjene učestale i brze.

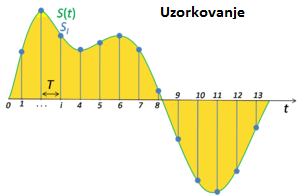
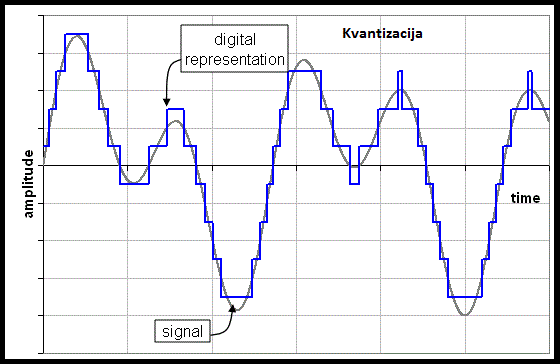
Kad smo već ušli u kodiranje videa, valja reći da postoji više vrsta kompresije koja s namjerom očiglednog pogoršanja kvalitete donosi znatno smanjenje u veličini tog zapisa. Kada bismo uspoređivali originalan zapis te ovaj nakon kompresije, vidjeli bismo da je ovaj drugi više “pikselast” odnosno da smo dijelove informacija u njemu izgubili. Opet ti dijelovi informacija se ne gube po nekom nasumičnom principu, već se radi o postupku kvantizacije i uzorkovanju što su osnovni procesi za video kodiranje, audio, slikovno itd. Kako računalo ipak ima konačnu količinu podataka koju može zapisati u memoriju, nužno je provesti ova dva postupka da bi se određena informacija mogla pretvoriti u nule i jedinice, odnosno zapis koji naša računala razumiju. Tako uslikamo li neki prizor s digitalnim fotoaparatom onda će se stvarna fizička slika u obliku kontinuiranog signala kakav postoji u prirodi uzorkovati, odnosno od tog signala uzeti će se uzorci u određenim intervalima te spremiti u memoriju. Drugo ograničenje računala protiv stvarne okoline je to što ono može zapisati konačnu vrijednost nekog podatka u memoriju što znači da moramo odrediti do koje ćemo preciznosti naše podatke zapisivati i na što ih zaokružiti. Tu dolazimo do ovog drugog postupka – kvantizacije. Radi se o tome da moramo odrediti broj bitova koji će se koristiti za zapisivanje određene informacije našeg zapisa. Ako uzmemo više bitova zvuk će biti jasniji, slika i video čišći s više detalja i tako dalje. Posljedica je naravno povećanje veličine te datoteke jer smo koristili više bitova za zapis iste informacije. Ovaj opis nastanka nekih od spomenutih formata u stvarnosti je dosta složeniji i koderi koji obavljaju ovdje navedene informacije razvijaju se i unaprjeđuju desetljećima. Za razliku od njihovog posla koji je uistinu kompleksan na idućem primjeru ćemo pokazati jedan osnovni primjer kompresije tekstualnih podataka, a čak i za takvo nešto što se na prvi pogled čini banalno, trebati će nam i nešto malo teorije vjerojatnosti. Neka vas sve ovo previše ne brine jer primjer je zato da pokaže neke temeljne principe kompresije, a sve ostalo se onda nadovezuje na to. Jedan od bitnijih termina ovdje je model po kojem se kompresija namjerava izvesti. Obično imamo neku distribuciju ili raspodjelu ponavljanja određenog simbola te po tome kodiramo određenu riječ. Načelno, za one simbole koji su učestaliji od drugih upotrijebiti ćemo manje bitova, dok za one rjeđe će biti potrebno više. Recimo da je naša riječ nad kojoj ćemo napraviti ovaj zahvat ‘abac’. U ovoj riječi imamo po dva puta slovo ‘a’ te jednom ‘b’ i ‘c’. Nije nam čak niti potrebna neka komplicirana teorija vjerojatnosti da iz ovoga izvučemo vjerojatnost ponavljanja pojedinog simbola, što bi u ovom slučaju bilo: ‘a’ – 1/2, ‘b’-1/4 i ‘c’-1/4. Dakle postoji 50% šanse da idući simbol bude ‘a’, te po 25% za preostale ‘b’ i ‘c’. S obzirom da smo rekli kako ćemo ovim učestalijim pridružiti manje bitova, odredimo za simbol ‘a’ kodnu riječ ’11’ te za ‘b’ stavimo ‘001’, a za ‘c’ onda ‘010’. Ako su svi znakovi jednako zastupljeni odnosno imaju istu vjerojatnost pojavljivanja, tada nećemo niti moći postići neki odgovarajući omjer kompresije, a više o tome govori disciplina teorije informacije u što sada nećemo dublje ulaziti. Pri dodjeli kodnih riječi treba paziti da jedna kodna riječ nije ujedno i prefiks druge jer u tom slučaju ne bismo mogli znati gdje jedna riječ završava, a druga počinje. I sada imamo kodiran niz znakova ‘abac’. Ušteda se očituje kada bismo imali ostatak teksta te kada bi se ponovno pojavio ovaj niz znakova mogli bismo cijelom nizu dodijeliti jednu kodnu riječ te tako za svaki idući niz. Sve kreće od prvog znaka – ‘a’ kojem dodijelimo kodnu riječ. Potom gledamo idući ‘ab’ te ga opet spremimo i sada svaki put u ostatku niza ako se pojavi ‘ab’ možemo iskoristiti riječ koju smo već definirali ranije. U idućim iteracijama vidjeli bismo da nemamo definiran ‘b’, niti ‘aba’ i tako se postupak ponavlja do kraja niza. U stvarnom svijetu te duljine što su podaci duži, postanu dosta velike i ušteda postane značajna vrlo brzo.

Nakon malo računanja prijeđimo na nešto manje zahtjevno, mjerenje kompresije tj. koliki nam je omjer kompresije. Logična mjera glasila bi duljina kompresiranih podataka podijeljeno s originalnom duljinom te rezultat možemo pomnožiti s 8 da dobijemo bajtove. Da bude malo jasnije ukoliko imamo originalnu duljinu od 1000 bajtova te nakon kompresije dobijemo duljinu od 500 bajtova, to ispada 0.5*8 ili 4, tj. potrebno nam je 4 bita za opisivanje jednog okteta. Obično se formula koristi u malo okrenutom obliku iz kojega se onda može očitati duljina izlaznog toka podataka ukoliko nam je poznata učinkovitost algoritma koji se koristi, što obično je slučaj. Postoje još dva popularna načina mjerenja, apsolutni koji gleda u postocima koliko smo dobili kompresijom, što bi u našem prethodnom slučaju bilo 500/1000, odnosno 50%. Drugi način ćete češće vidjeti kod primjerice video kodiranja u aplikacijama koje daju neki izlazni video format pa piše nešto poput 2.5:1 ili 2:1 i slično. Ove oznake znače da je originalna veličina smanjena na polovičnu, u posljednjem primjeru.
Sada s još boljim uvidom u kompresiju, idemo još malo vidjeti njenu upotrebu u svakodnevnom radu na računalu, odnosno sada možemo bolje pronaći njene prednosti u primjenama kojih nismo niti svjesni. Dakle, što sve možemo pustiti kroz kompresiju? Spomenuli smo video, audio, slikovne datoteke te tekstualne datoteke. Tu priča tek kreće, a svaka od tih stavki ima više načina i algoritama po kojima se kompresija može izvršiti ovisno o cilju. Jedan od primjera su i web stranice koje u određenim slučajevima prolaze proces kompresije podataka, odnosno za vrijeme prikazivanja u pregledniku se izvlači taj sadržaj, a cijeli je postupak nevidljiv korisniku. U ovom slučaju posljedica je brže učitavanje sadržaja. Dobar primjer su i računalne igre koje također rade kompresiju nad određenim podacima, samo ovdje se to ne radi toliko zbog veličine podataka, već zbog fragmentacije tj. njihovog bržeg pristupa čitanju. Neki od ostalih primjera su i video zapisi koje pronalazimo na Internetu, optički mediji, a pošteđeni nisu niti mobilni uređaji te ste mogli primijetiti da sve današnje platforme čak sadrže i neki od programa za čitanje i stvaranje ZIP arhiva. Kod mobilnih uređaja kompresija se koristi u mobilnom Internetu, pozivima, slikama, videu i drugim aspektima. Uz tematiku su usko vezane i arhive poput ZIP-a, gdje se uz određeni stupanj kompresije ide i prema organizaciji podataka. Vratimo li se malo na primjer s igrama, možete u velikoj većini primijetiti kako su grafički elementi, teksture i slično organizirani u arhive kako bi im se brže pristupilo te obično postoji postupak njihovog predučitavanja u memoriju kada će pojedine biti korištene. Ovaj postupak uvelike ubrzava igru, nego da imamo slučaj kada bi te datoteke bile loše razmještene pri čemu bi se ponajviše vremena gubilo na njihovo traženje i potom pristup svakoj. Nadam se da ste dobili neki bolji dojam u rad računala s kompresijskim algoritmima i značaj tog procesa i kroz povijest, a i u današnje vrijeme.

